그룹핑 한 후 순번을 매겨주는 함수
SELECT ROW_NUMBER( ) OVER ( PARTITION BY 그룹핑할 칼럼 ORDER BY 정렬할 칼럼 )
FROM 테이블명
( ORDER BY 정렬할 칼럼 DESC or ASC or 생략하면 ASC가 디폴트값 )
이 긴 함수가 한 세트~
PARTITION BY 에 지정한 칼럼 기준으로 그룹핑 해주고
ORDER BY 에 지정한 칼럼 기준으로 정렬해준담에
ROW_NUMBER 행 마다 순서를 매겨준다
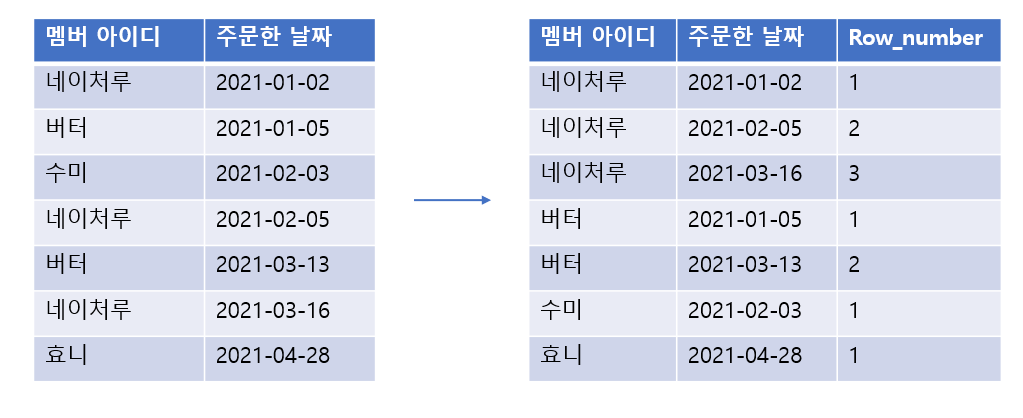
예를 들어
아래 왼쪽 테이블을 오른쪽 테이블 같이 그룹핑, 정렬 해주고 싶으면
이렇게 함수를 작성하면 된다.
ROW_NUMBER( ) OVER (PARTITION BY '멤버 아이디' ORDER BY '주문한 날짜')
실무에 사용되는 쿼리문을 통해 한번 더 확인해 보자
select substring(o.od_receipt_time, 1,10) as dt
, m.mb_id
, o.od_receipt_price
, row_number() over (partition by m.mb_id order by o.od_receipt_time) as o_rn
from member m
join order o
on m.mb_id = o.mb_id멤버 테이블과 주문 테이블을 멤버아이디 (mb_id) 로 join 한 후
4개의 칼럼 select !
그 중 한 칼럼은 row_number () over (partition by order by) 를 사용해서 결과를 얻은 칼럼! o_rn 으로 명명.

위 예시 쿼리문에서 사용된
row_number( ) over (partition by m.mb_id order by o.od_receipt_time)
이 함수를 보면
partition by m.mb_id mb_id 컬럼 기준으로 그룹핑 한다음에
order by o.od_receipt_time od_receipt_time 컬럼 기준으로 정렬해서
row_number( ) 순서를 매겨줬다
이렇게 나온 테이블을 서브쿼리로 사용하여
일별 신규주문, 재주문 주문수, 주문금액을 구해보자
select dt
, count(*) as total_order_
, sum(case when o_rn = 1 then 1 else 0 end) as new_order -- 해당날짜에 o_rn 이 1이면 1 반환하고 모두 더한다
, sum(case when o_rn = 1 then 0 else 1 end) as re_order -- 해당날짜에 o_rn 이 1이 아니면 1 반환하고 모두 더한다
, sum(od_receipt_price) as total_price
, sum(case when o_rn = 1 then od_receipt_price else 0 end) as new_price
, sum(case when o_rn = 1 then 0 else od_receipt_price end) as re_price
from (select substring(o.od_receipt_time, 1,10) as dt
, m.mb_id
, o.od_receipt_price
, row_number() over (partition by m.mb_id order by o.od_receipt_time) as o_rn
from member m
join order o
on m.mb_id = o.mb_id) s1
group by dt
order by 1; -- 첫번째 컬럼 기준으로 정렬하라는 거 즉 dt 기준으로

이렇게 결과를 볼 수 있다.
위 쿼리문은 AWS Redshift 가 사용하는 PL/pgSQL 언어에서 돌아가는 쿼리문이고
MySQL 을 사용한다면 아래와 같이 작성하면 된다
select dt
, count(*) as total_order_
, count(if(o_rn = 1, 1, null)) as new_order
, count(if(o_rn = 1, null, 1)) as re_order
, sum(od_receipt_price) as total_price
, sum(if(o_rn = 1, od_receipt_price, 0)) as new_price
, sum(if(o_rn = 1, 0, od_receipt_price)) as re_price
from (select date_format(o.od_receipt_time, '%Y-%m-%d') as dt
, m.mb_id
, o.od_receipt_price
, row_number() over (partition by m.mb_id order by o.od_receipt_time) as o_rn
from member m
join order o
on m.mb_id = o.mb_id) s1
group by dt
order by 1;
참고 )
order by 1 은 첫번째 칼럼 즉 dt 칼럼 기준으로 정렬하라는 뜻이다.
만일 order by 2 라고 쓰면 위 select 문에서 2번째 칼럼인 total_order_ 기준으로 정렬하라는 뜻
RANK() OVER (Partition by _ Order by _)
와의 차이점은
ROW_NUMBER( ) : 1등이 2명이어도 1등, 2등으로 나눔
RANK( ) : 1등이 2명이면 그 다음 순위는 3등으로 매김
'IT > SQL' 카테고리의 다른 글
| [SQL 예문] 브랜드별 판매수량, 금액 구하기 (feat. JOIN) (0) | 2022.03.18 |
|---|---|
| [SQL 함수] RANK() OVER (Partition by _ Order by _ ) (0) | 2022.03.14 |
| [AWS Redshift SQL] DATEDIFF 함수 _ 날짜 차이 구하기 (1) | 2022.03.08 |
| [AWS Redshift SQL] 숫자 세 자리 마다 콤마(,) 찍기 / 소수점 자릿수 맞추기 (ft. TO_CHAR) (0) | 2022.03.07 |
| [AWS] Redshift 는 PostgreSQL을 기반으로 한다 (0) | 2022.03.04 |




댓글